Modelling a region of the chromatin¶
Load previous data¶
from pytadbit import load_chromosome
from pytadbit.parsers.hic_parser import load_hic_data_from_bam
crm = load_chromosome('results/fragment/chr3.tdb')
B, PSC = crm.experiments
B, PSC
(Experiment mouse_B (resolution: 100 kb, TADs: 96, Hi-C rows: 1601, normalized: None), Experiment mouse_PSC (resolution: 100 kb, TADs: 118, Hi-C rows: 1601, normalized: None))
Load raw data matrices, and normalized matrices
base_path = 'results/fragment/{0}_both/03_filtering/valid_reads12_{0}.bam'
bias_path = 'results/fragment/{0}_both/04_normalizing/biases_{0}_both_{1}kb.biases'
reso = 100000
chrname = 'chr3'
cel1 = 'mouse_B'
cel2 = 'mouse_PSC'
hic_data1 = load_hic_data_from_bam(base_path.format(cel1),
resolution=reso,
region='chr3',
biases=bias_path.format(cel1, reso // 1000),
ncpus=8)
hic_data2 = load_hic_data_from_bam(base_path.format(cel2),
resolution=reso,
region='chr3',
biases=bias_path.format(cel2, reso // 1000),
ncpus=8)
(Matrix size 1601x1601) [2020-02-06 16:50:49] - Parsing BAM (101 chunks) [2020-02-06 16:50:49] .......... .......... .......... .......... .......... 50/101 .......... .......... .......... .......... .......... 100/101 . 101/101 - Getting matrices [2020-02-06 16:50:52] .......... .......... .......... .......... .......... 50/101 .......... .......... .......... .......... .......... 100/101 . 101/101 (Matrix size 1601x1601) [2020-02-06 16:50:56] - Parsing BAM (101 chunks) [2020-02-06 16:50:56] .......... .......... .......... .......... .......... 50/101 .......... .......... .......... .......... .......... 100/101 . 101/101 - Getting matrices [2020-02-06 16:51:00] .......... .......... .......... .......... .......... 50/101 .......... .......... .......... .......... .......... 100/101 . 101/101
B.load_hic_data([hic_data1.get_matrix(focus='chr3')])
B.load_norm_data([hic_data1.get_matrix(focus='chr3', normalized=True)])
PSC.load_hic_data([hic_data2.get_matrix(focus='chr3')])
PSC.load_norm_data([hic_data2.get_matrix(focus='chr3', normalized=True)])
Modeling¶
We use the best parameters obtained from the optimization process to produce an ensemble of models.
From the models produced (n_models) we will tell TADbit to conserve a number of them (n_keep) that best satisfy the imposed restraints.
optimal_params = {'dcutoff': 2.0,
'kbending': 0.0,
'kforce': 5,
'lowfreq': -0.6,
'maxdist': 2000.0,
'reference': 'Stadhouders R, Vidal E, Serra F, Di Stefano B et al. 2018',
'scale': 0.01,
'upfreq': 0.0}
models_B = B.model_region(start=300, end=360, n_models=400, n_keep=100, n_cpus=8,
config=optimal_params)
models_PSC = PSC.model_region(start=300, end=360, n_models=400, n_keep=100, n_cpus=8,
config=optimal_params)
The ensemble of models have inherited the description from the Chromosome object
print(models_B.description)
{'identifier': None, 'chromosome': 'chr3', 'start': 29900000, 'end': 36000000, 'species': None, 'restriction enzyme': None, 'cell type': None, 'experiment type': 'Hi-C', 'resolution': 100000, 'assembly': None}
We still can access to the experiment object from the 3D models:
print(models_B.experiment)
print(models_PSC.experiment)
Experiment mouse_B: resolution : 100 kb TADs : 96 Hi-C rows : 1601 normalized : visibility identifier : UNKNOWN cell type : UNKNOWN restriction enzyme: UNKNOWN Experiment mouse_PSC: resolution : 100 kb TADs : 118 Hi-C rows : 1601 normalized : visibility identifier : UNKNOWN cell type : UNKNOWN restriction enzyme: UNKNOWN
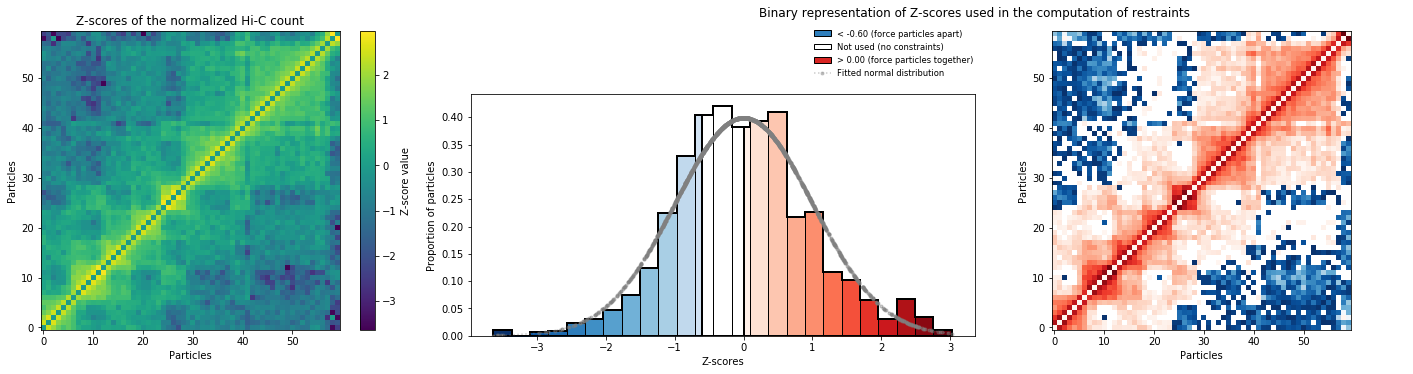
We can have a look at the data that was used to define restraints:
models_B.zscore_plot()
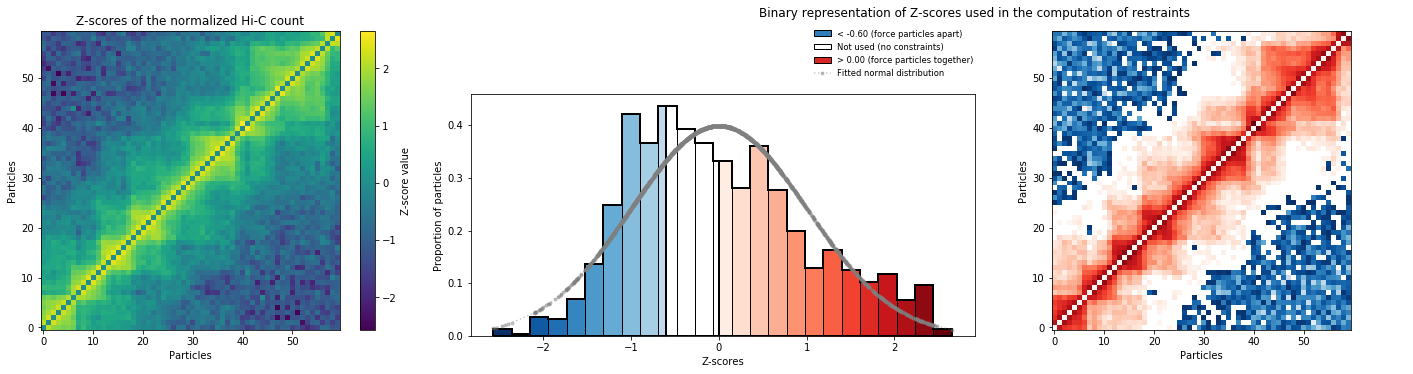
models_PSC.zscore_plot()
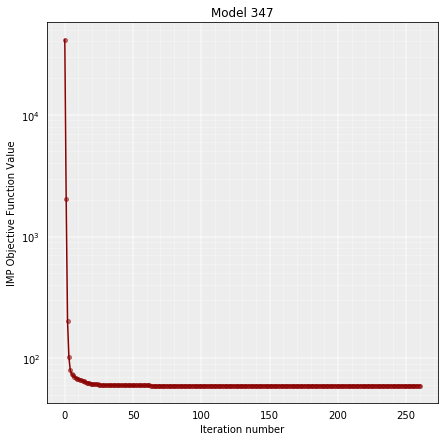
and also visualize how the IMP objective function (OF) of the stored model improves during the MOnte Carlo optimization:
model = models_B[0]
model.objective_function(log=True, smooth=False)
Structural Models¶
The definition of the “best models” can be changed at any time. Only the best models will be used in the analysis.
Select top 10 models
models_B.define_best_models(10)
print("Lowest 10 IMP OF models:")
print(models_B)
Lowest 10 IMP OF models:
StructuralModels with 10 models of 61 particles
(objective function range: 59 - 61)
(corresponding to the best models out of 100 models).
IMP modeling used this parameters:
- reference : Stadhouders R, Vidal E, Serra F, Di Stefano B et al. 2018
- kforce : 5
- scale : 0.01
- kbending : 0.0
- maxdist : 2.0
- lowfreq : -0.6
- upfreq : 0.0
- dcutoff : 2.0
- resolution : 100000
- container : {'shape': None, 'radius': None, 'height': None, 'cforce': None}
- lowrdist : 1.0
Models where clustered into 0 clusters
Select top 100 models
models_B.define_best_models(100)
print("Lowest 100 IMP OF models:")
print(models_B)
Lowest 100 IMP OF models:
StructuralModels with 100 models of 61 particles
(objective function range: 59 - 62)
(corresponding to the best models out of 100 models).
IMP modeling used this parameters:
- reference : Stadhouders R, Vidal E, Serra F, Di Stefano B et al. 2018
- kforce : 5
- scale : 0.01
- kbending : 0.0
- maxdist : 2.0
- lowfreq : -0.6
- upfreq : 0.0
- dcutoff : 2.0
- resolution : 100000
- container : {'shape': None, 'radius': None, 'height': None, 'cforce': None}
- lowrdist : 1.0
Models where clustered into 0 clusters
The ensemble of models “models_B” and “models_PSC” contain the models generated by the Montecarlo simulation ordered by its Objective Function (OF). The first model in the list is the one than best satisfies the imposed restraints.
To get the data for the lowest IMP OF model in the set of models we retrieve model number 0
model = models_B[0]
print(model)
IMP model ranked 1 (61 particles) with:
- Final objective function value: 59.917060532471695
- random initial value: 347
- first coordinates:
X Y Z
6106 -2093 -8118
5934 -2067 -7209
6763 -2547 -7196
We can check the correlation of models_B with the original HiC matrix.
In the plot “Real vs modelled data” we should see a positive correlation of the contacts in the models with the frequency of interaction of the pairs of beads in the HiC matrix. High interaction frequency between two loci in the matrix is reflected by the fact of having a high proportion of models where the beads representing those two loci are “in contact” (distance lower than the cutoff).
models_B.correlate_with_real_data(plot=True, cutoff=2000)
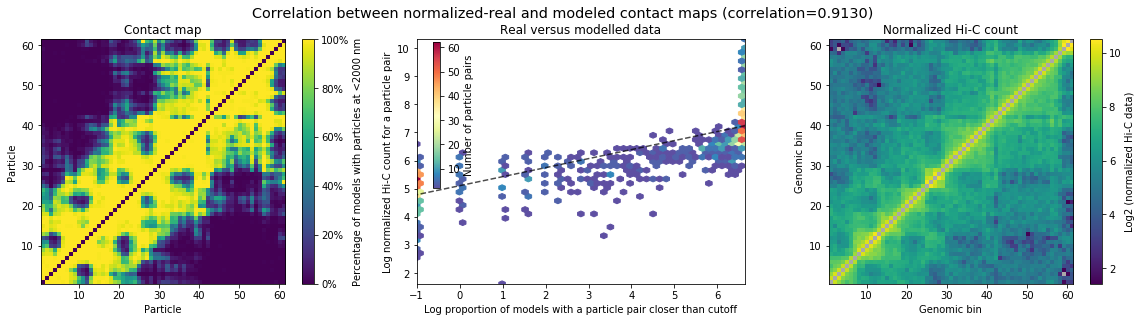
SpearmanrResult(correlation=0.9130233605402466, pvalue=0.0)
To plot all the models in the ensemble we use the view_models function. By default the centroid (the model closer to the median) is highlighted.
models_PSC.view_models(tool='plot')
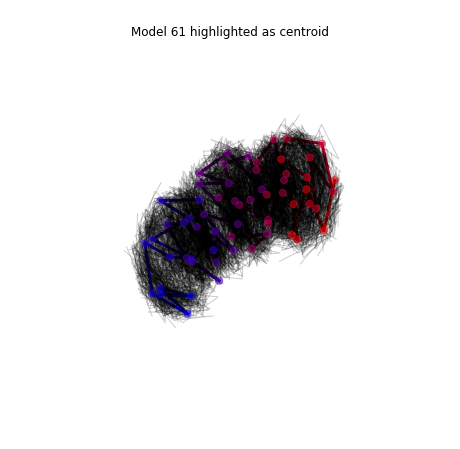
We can also plot individual models.
models_PSC.view_models(models=[0], tool='plot')

And use Chimera (https://www.cgl.ucsf.edu/chimera/) for the visualization of the 3D structure
models_PSC.view_models(models=[0], tool='chimera')
Model analysis¶
Align models¶
In the Montecarlo simulation each of the models is built starting from a random initial conformation. Therefore models are not aligned in a preferred orientation. We can use the function align_models to rotate and translate the coordinates of the models so they follow the same orientation as one of the models in the ensemble. By default the model used as reference is the first one.
models_PSC.align_models(in_place=True)
With the function deconvolve we obtain a deconvolution analysis of a given froup of models.It first clusters models based on structural comparison (dRMSD). Differential contact map between each possible pair of clusters is shown in the resulting graph. This allows us to detect common sets of contacts in the ensemble.
Deconvolve¶
models_PSC.deconvolve(fact=0.35, dcutoff=2000, represent_models='best', n_best_clusters=5)
Total number of clusters: 8 Cluster #1 has 5 models [top model: 66] Cluster #2 has 5 models [top model: 237] Cluster #3 has 4 models [top model: 269] Cluster #4 has 3 models [top model: 191] Cluster #5 has 3 models [top model: 61] Cluster #6 has 2 models [top model: 175] Cluster #7 has 2 models [top model: 396] Cluster #8 has 2 models [top model: 152]
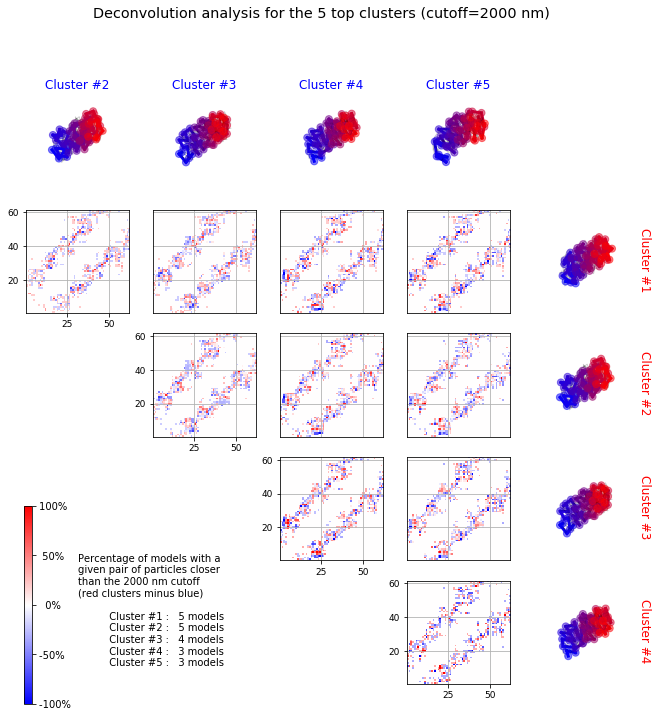
Clustering¶
The clustering of the models by Markov Cluster Algorith (MCL) or Ward can be based on different statistics measures (score, rmsd, drmsd or eqv). By default a score computed as a combination of rmsd, drmsd and eqv is used.
# Cluster models based on structural similarity
models_B.cluster_models(fact=0.95, dcutoff=1000)
print(models_B.clusters)
Number of singletons excluded from clustering: 0 (total singletons: 0) Total number of clusters: 2 Cluster #1 has 50 models [top model: 396] Cluster #2 has 50 models [top model: 347] Total number of clusters: 2 Cluster #1 has 50 models [top model: 396] Cluster #2 has 50 models [top model: 347]
The analysis dendogram allows us to view the different clusters population and their OF values.
# Plot the resulting clusers
cl = models_B.cluster_analysis_dendrogram()
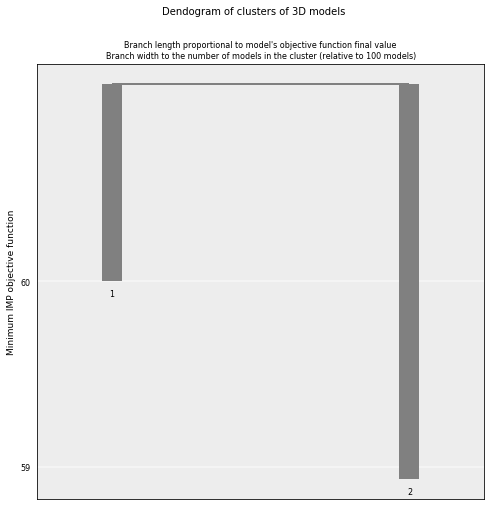
# Cluster models based on structural similarity
models_PSC.cluster_models(fact=0.95, dcutoff=1000)
print(models_PSC.clusters)
Number of singletons excluded from clustering: 64 (total singletons: 64) Total number of clusters: 11 Cluster #1 has 5 models [top model: 159] Cluster #2 has 5 models [top model: 232] Cluster #3 has 4 models [top model: 46] Cluster #4 has 4 models [top model: 54] Cluster #5 has 4 models [top model: 279] Cluster #6 has 3 models [top model: 191] Cluster #7 has 3 models [top model: 135] Cluster #8 has 2 models [top model: 378] Cluster #9 has 2 models [top model: 59] Cluster #10 has 2 models [top model: 152] Cluster #11 has 2 models [top model: 29] Total number of clusters: 11 Cluster #1 has 5 models [top model: 159] Cluster #2 has 5 models [top model: 232] Cluster #3 has 4 models [top model: 46] Cluster #4 has 4 models [top model: 54] Cluster #5 has 4 models [top model: 279] Cluster #6 has 3 models [top model: 191] Cluster #7 has 3 models [top model: 135] Cluster #8 has 2 models [top model: 378] Cluster #9 has 2 models [top model: 59] Cluster #10 has 2 models [top model: 152] Cluster #11 has 2 models [top model: 29]
# Plot the resulting clusers
cl = models_PSC.cluster_analysis_dendrogram()
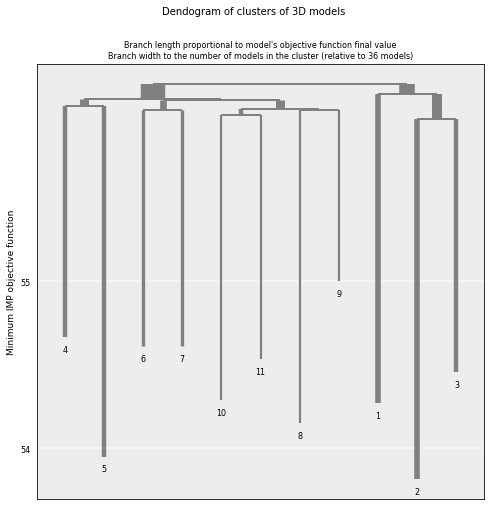
Consistency¶
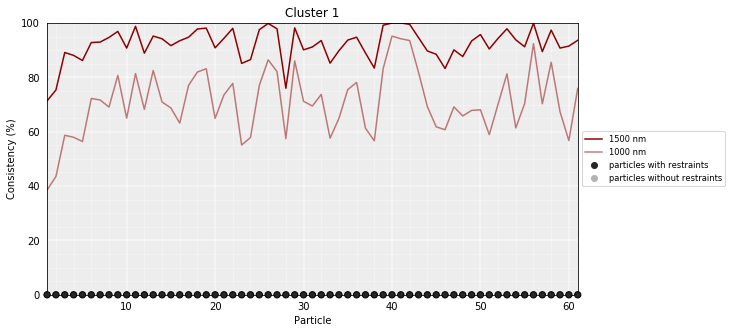
Model consistency gives a measure of the variability of the particles accross a set of models. Particles in the same position accross different models are considered consistent if their distance is less than the given cutoff.
# Calculate the consistency plot for all models in the first cluster (cluster 0)
models_B.model_consistency(cluster=1, cutoffs=(1000,1500))
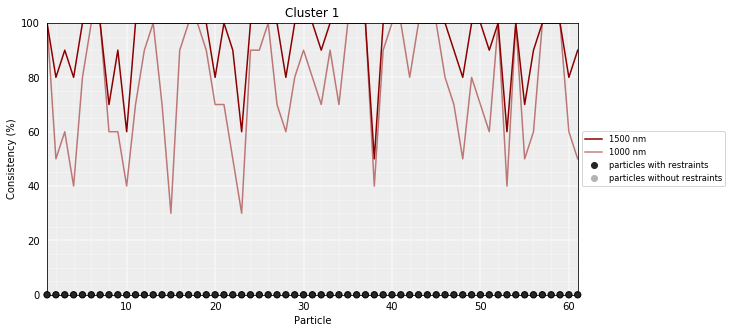
# Calculate the consistency plot for all models in the first cluster (cluster 0)
models_PSC.model_consistency(cluster=1, cutoffs=(1000,1500))
DNA density plots¶
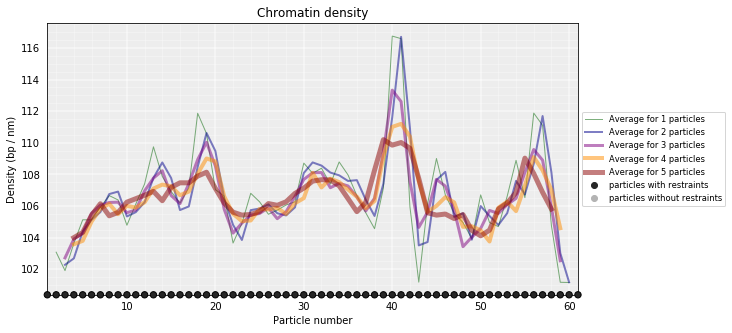
From the 3D models, the DNA density (or local compactness) can be calculated as the ratio of the bin size (in base pairs) and the distances between consequtive particles in the models. The higher the density the more compact DNA for the region. As this measure varies dramatically from particle to particle, one can calculate it using running averages.
In the modelling we have used a scale of 0.01 nm/bp; that means that if we expect 100 bp/nm of chromatin in each bead and between two consecutives beads.
# Calculate a DNA density plot
models_B.density_plot(cluster=1)
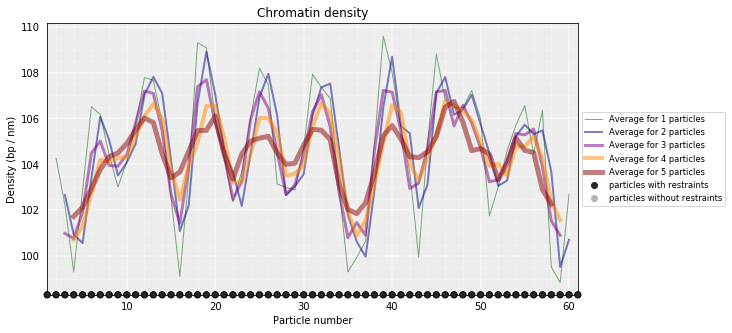
# Calculate a DNA density plot
models_PSC.density_plot()
# Get a similar plot for only the top cluster and show the standar deviation for a specific(s) running window (steps)
models_B.density_plot(cluster=1,error=True, steps=(5))
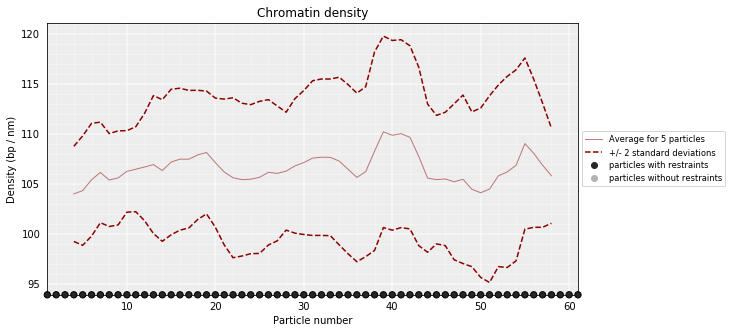
# Get a similar plot for only the top cluster and show the standar deviation for a specific(s) running window (steps)
models_PSC.density_plot(cluster=1,error=True, steps=(5))
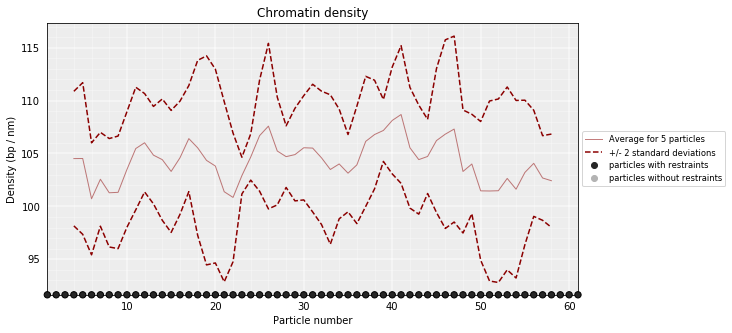
Walking Angle¶
Walking_angle plots the angle between triplets of contiguous particles. The higher are these values the straighter are the models.
models_B.walking_angle(steps=(3, 5, 7), signed=False)
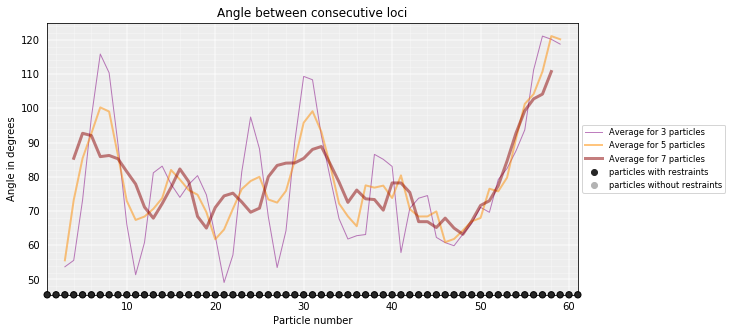
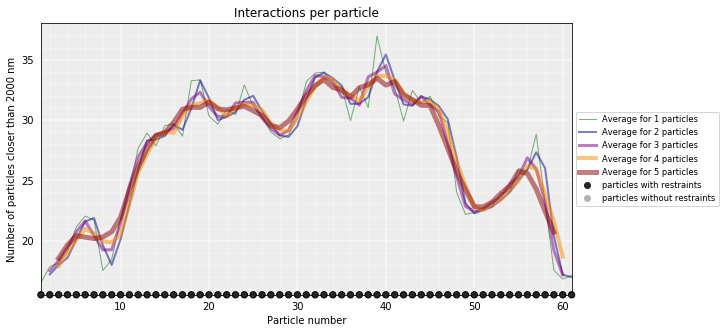
Particles interactions¶
We can plot for each particle the number of interactions (particles closer than the given cutoff)
models_B.interactions(cutoff=2000)
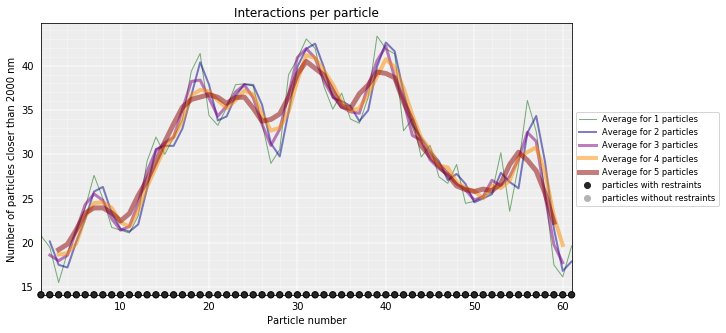
models_PSC.interactions(cutoff=2000)
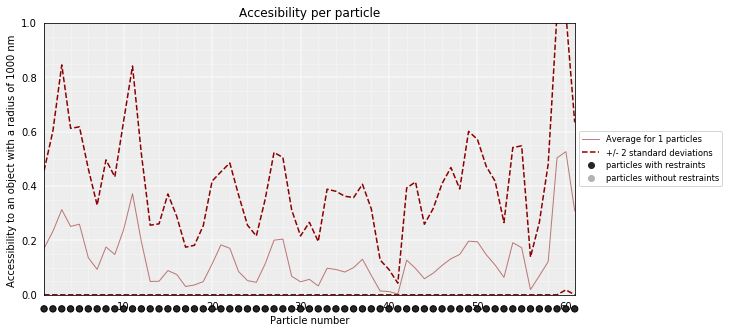
Accessibility¶
The accessibility is calculated by considering a mesh surface around the model and checking if each point of this mesh could be replaced by an object (i.e. a protein) represented as a sphere of a given radius.
Outer part of the model can be excluded from the estimation of accessible surface because contacts from this outer part to particles outside the model are unknown. To exclude the outer contour a sphere with a higher radius (superradius) is first tested in the mesh before proceding to the accessibility calculation.
models_B.accessibility(cluster=1, radius=1000, nump=10, superradius=2000)
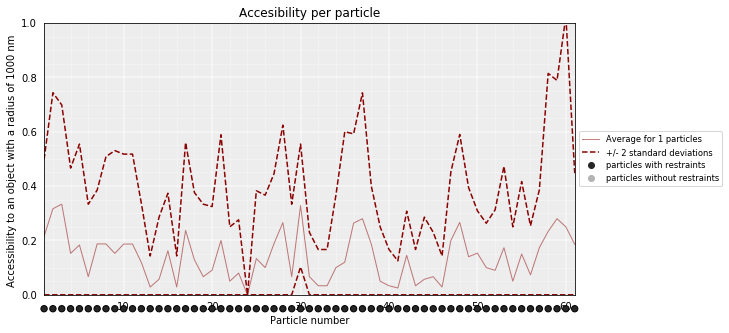
models_PSC.accessibility(cluster=1, radius=1000, nump=10, superradius=2000)
Calculating distances between particles¶
To inspect the distance between two particles in the models we can use the median_3d_dist function which give us not only the median distance considering all the models but also an histogram of the different values accross them.
models_B.median_3d_dist(13, 20, plot=False)
1618.4735489472441
models_B.median_3d_dist(13, 20, plot=True)
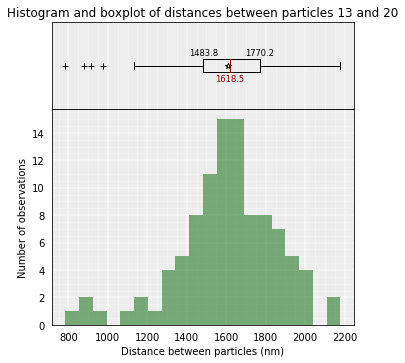
models_PSC.median_3d_dist(13, 20, plot=True)
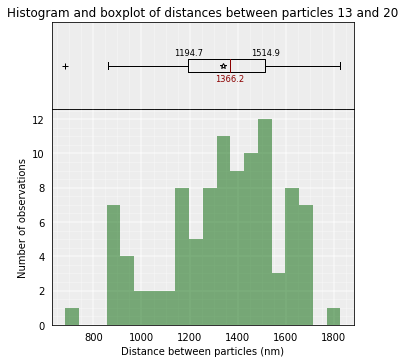
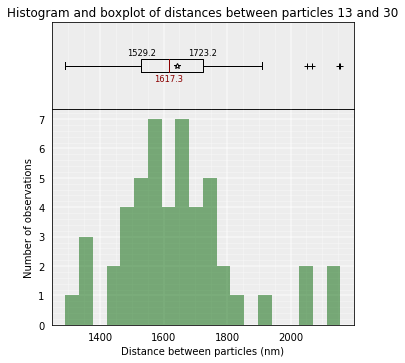
The median distance can be calculated only in one of the clusters or in a set of models.
models_B.median_3d_dist(13, 30, cluster=1)
models_B.median_3d_dist(13, 30, models=[0,1,2,3,4,5])
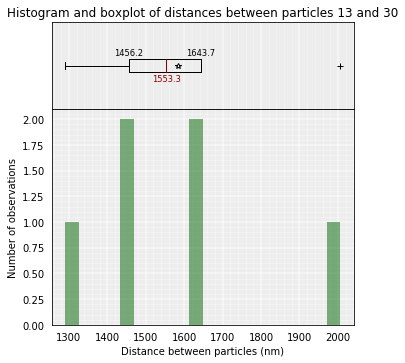
The Structural Models object can be saved and retrieved at a later stage
# Save your entire analysis and models
models_B.save_models('B.models')
from pytadbit import load_structuralmodels
# Load the models
loaded_models = load_structuralmodels('B.models')
print(loaded_models)
StructuralModels with 100 models of 61 particles
(objective function range: 59 - 62)
(corresponding to the best models out of 100 models).
IMP modeling used this parameters:
- reference : Stadhouders R, Vidal E, Serra F, Di Stefano B et al. 2018
- kforce : 5
- scale : 0.01
- kbending : 0.0
- maxdist : 2.0
- lowfreq : -0.6
- upfreq : 0.0
- dcutoff : 2.0
- resolution : 100000
- container : {'shape': None, 'radius': None, 'height': None, 'cforce': None}
- lowrdist : 1.0
Models where clustered into 2 clusters
Other information can also be saved independently like the contacts map as a bed-like file, the models either as a xyz bed-like file or as cmm to visualize with Chimera.
We can also export the models and clusters to a JSON for a later inspection with TADkit (http://sgt.cnag.cat/3dg/tadkit/)
! mkdir -p results/models_B
models_B.experiment
Experiment mouse_B (resolution: 100 kb, TADs: 96, Hi-C rows: 1601, normalized: visibility)
models_B.contact_map(models=range(5,10), cutoff=2000, savedata="results/models_B/contact.txt")
# Write a CMM file for the top model
models_B.write_cmm(directory="results/models_B", model_num=0)
# Write CMM ofcentroid model
models_B.write_cmm(directory="results/models_B", model_num=models_B.centroid_model(cluster=1))
# Write a XYZ file for the top model
models_B.write_xyz(directory="results/models_B", model_num=0)
# Write a XYZ file for the top 10 models
models_B.write_xyz(directory="results/models_B", models=range(10))
# Write a XYZ file for the cluster 1 models
models_B.write_xyz(directory="results/models_B", cluster=1)
# Write TADkit JSON http://sgt.cnag.cat/3dg/tadkit/demo.h/
models_B.description['species'] = 'Mus Musculus'
models_B.write_json(filename="results/models_B/models_B.json", title="Mouse B")
/home/dcastillo/miniconda2/envs/py3_tadbit/lib/python3.7/site-packages/pytadbit/modelling/structuralmodels.py:2557: UserWarning: WARNING: chrom_start variable wasn't set, setting it to the position in the experiment matrix (29900000) if isinstance(my_descr['start'], list) else my_descr['start']))) /home/dcastillo/miniconda2/envs/py3_tadbit/lib/python3.7/site-packages/pytadbit/modelling/structuralmodels.py:2563: UserWarning: WARNING: chrom_end variable wasn't set, setting it to the position in the experiment matrix (36000000) if isinstance(my_descr['end'], list) else my_descr['end'])))
! mkdir -p results/models_PSC
models_PSC.description['species'] = 'Mus Musculus'
models_PSC.write_json(filename="results/models_PSC/models_PSC.json", title="Mouse PSC")
/home/dcastillo/miniconda2/envs/py3_tadbit/lib/python3.7/site-packages/pytadbit/modelling/structuralmodels.py:2557: UserWarning: WARNING: chrom_start variable wasn't set, setting it to the position in the experiment matrix (29900000) if isinstance(my_descr['start'], list) else my_descr['start']))) /home/dcastillo/miniconda2/envs/py3_tadbit/lib/python3.7/site-packages/pytadbit/modelling/structuralmodels.py:2563: UserWarning: WARNING: chrom_end variable wasn't set, setting it to the position in the experiment matrix (36000000) if isinstance(my_descr['end'], list) else my_descr['end'])))
